
![]() Apache Hadoop是一款支持数据密集型分布式应用并以Apache 2.0许可协议发布的开源软件框架。它支持在商品硬件构建的大型集群上运行的应用程序。Hadoop是根据Google公司发表的MapReduce和Google文件系统的论文自行实现而成。到目前为止的最新版本为3.0.0-alpha1(03 September, 2016)。Hadoop适合应用于大数据存储和大数据分析的应用,适合于服务器几千台到几万台的集群运行,支持PB级的存储容量
Apache Hadoop是一款支持数据密集型分布式应用并以Apache 2.0许可协议发布的开源软件框架。它支持在商品硬件构建的大型集群上运行的应用程序。Hadoop是根据Google公司发表的MapReduce和Google文件系统的论文自行实现而成。到目前为止的最新版本为3.0.0-alpha1(03 September, 2016)。Hadoop适合应用于大数据存储和大数据分析的应用,适合于服务器几千台到几万台的集群运行,支持PB级的存储容量
Apache Hadoop的框架有下面部分组成
Hadoop Common: The common utilities that support the other Hadoop modules.
Hadoop Distributed File System (HDFS): A distributed file system that provides high-throughput
access to application data
Hadoop YARN: A framework for job scheduling and cluster resource management
Hadoop MapReduce: A YARN-based system for parallel processing of large data sets
A. 在0.20及以前的版本中,包含HDFS、MapReduce和其他项目公共内容,从0.21开始HDFS和MapReduce被分离为独立的子项目,其余内容为Hadoop Common
B. Mapreduce并行计算框架,0.20前使用org.apache.hadoop.mapred旧接口,0.20版本开始引入了新的API org.apache.hadoop.mapreduce
C. Hadoop 2.0引入了YARN
Hadoop的核心就是HDFS和MapReduce
HDFS:被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。HDFS是Apache Hadoop Core项目的一部分。这个项目的地址是http://hadoop.apache.org/core/。MapReduce的基本原理就是:将大的数据分析分成小块逐个分析,最后再将提取出来的数据汇总分析,最终获得我们想要的内容。怎么做Reduce操作非常复杂,Hadoop已经提供了数据分析的实现,我们只需要编写简单的需求命令即可达成我们想要的数据
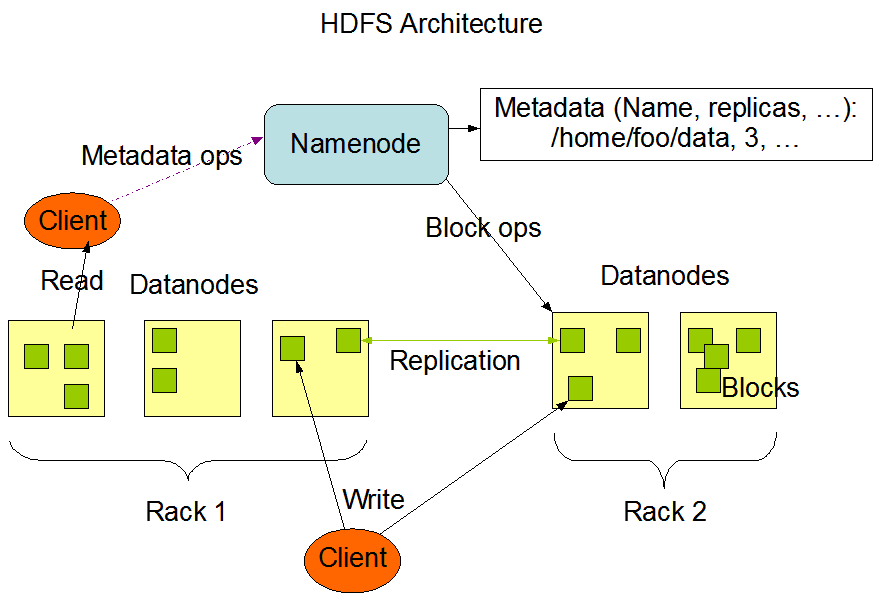
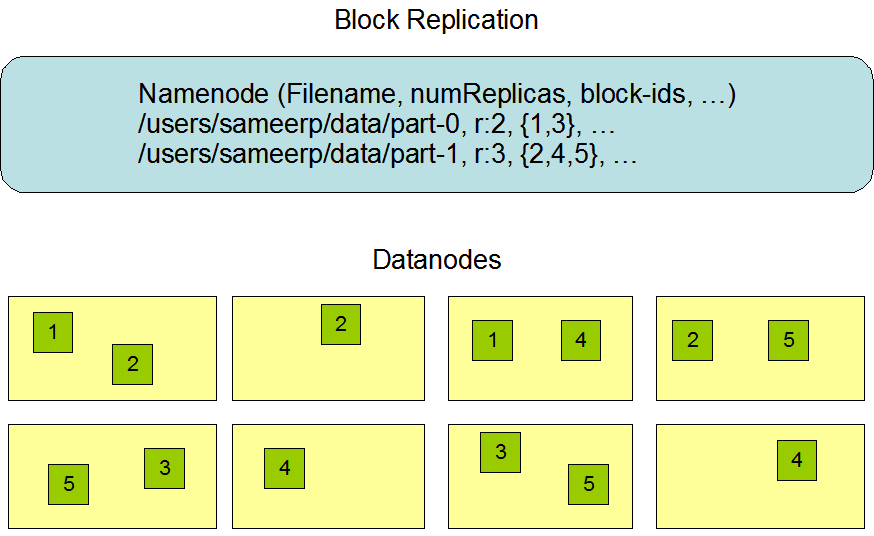
Map/Reduce:是一个使用简易的软件框架,基于它写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理上T级别的数据集。
一个Map/Reduce 作业(job)通常会把输入的数据集切分为若干独立的数据块,由 map任务(task)以完全并行的方式处理它们。框架会对map的输出先进行排序, 然后把结果输入给reduce任务。通常作业的输入和输出都会被存储在文件系统中。 整个框架负责任务的调度和监控,以及重新执行已经失败的任务。
YARN(Yet Another Resource Negotiator)
Hadoop 2.0引入了YARN,它的基本设计思想是将MRv1中的JobTracker拆分成了两个独立的服务:一个全局的资源管理器Resource Manager和每个应用程序特有的Application Master。其中Resource Manager负责整个系统的资源管理和分配,而Application Master负责单个应用程序的管理。
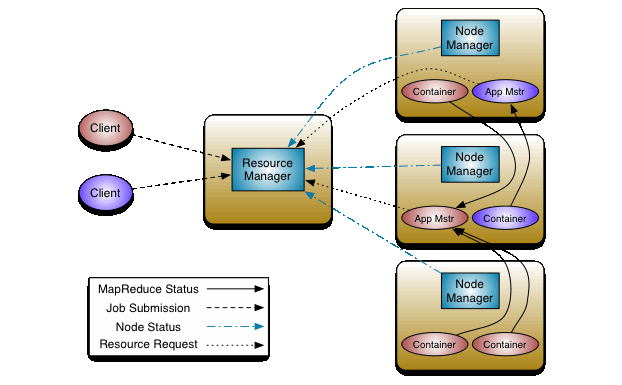
Apache Hadoop相关的其他项目
Ambari: A web-based tool for provisioning, managing, and monitoring Apache Hadoop clusters which includes support for Hadoop HDFS, Hadoop MapReduce, Hive, HCatalog, HBase, ZooKeeper, Oozie, Pig and Sqoop. Ambari also provides a dashboard for viewing cluster health such as heatmaps and ability to view MapReduce, Pig and Hive applications visually alongwith features to diagnose their performance characteristics in a user-friendly manner.
Avro: A data serialization system.
Cassandra: A scalable multi-master database with no single points of failure.
Chukwa: A data collection system for managing large distributed systems.
HBase: A scalable, distributed database that supports structured data storage for large tables.
Hive: A data warehouse infrastructure that provides data summarization and ad hoc querying.
Mahout: A Scalable machine learning and data mining library.
Pig: A high-level data-flow language and execution framework for parallel computation.
Spark: A fast and general compute engine for Hadoop data. Spark provides a simple and expressive programming model that supports a wide range of applications, including ETL, machine learning, stream processing, and graph computation.
Tez: A generalized data-flow programming framework, built on Hadoop YARN, which provides a powerful and flexible engine to execute an arbitrary DAG of tasks to process data for both batch and interactive use-cases. Tez is being adopted by Hive™, Pig™ and other frameworks in the Hadoop ecosystem, and also by other commercial software (e.g. ETL tools), to replace Hadoop™ MapReduce as the underlying execution engine.
ZooKeeper: A high-performance coordination service for distributed applications.
Hadoop快速入门中文手册
http://hadoop.apache.org/docs/r1.0.4/cn/quickstart.html
下载Hadoop
| Version | Release Date | Tarball |
| 3.0.0-alpha1 | 03 September, 2016 | source |
|
|
binary | |
| 2.7.3 | 25 August, 2016 | source |
|
|
binary | |
| 2.6.5 | 08 October, 2016 | source |
|
|
binary | |
| 2.5.2 | 19 Nov, 2014 | source |
|
|
binary | |
关于Cloudera公司
2008年,几位来自硅谷顶尖企业的优秀人才共同创建了Cloudera,包括来自Google的Christophe
Bisciglia、来自Yahoo的Amr Awadallah、来自Oracle的Mike Olson(Berkeley
DB的创始人,2006年被甲骨文收购)和来自Facebook的Jeff Hammerbacher。2009年Doug
Cutting作为首席架构师加入Cloudera,到目前仍保持着这一角色。Cloudera的开源Apache
Hadoop发行版,即(Cloudera Distribution including Apache
Hadoop,CDH),面向Hadoop企业级部署。向企业客户提供基于Apache
Hadoop的软件、支持、服务以及培训。同时Cloudera是Apache软件基金会的赞助商
Reference
https://en.wikipedia.org/wiki/Doug_Cutting
http://hadoop.apache.org/releases.html
https://en.wikipedia.org/wiki/Apache_Hadoop
https://zh.wikipedia.org/wiki/Apache_Hadoop
http://baike.baidu.com/view/908354.htm
http://hadoop.apache.org/docs/
https://en.wikipedia.org/wiki/Cloudera
http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/
http://hortonworks.com/blog/apache-hadoop-yarn-concepts-and-applications/
http://www.jianshu.com/p/c97ff0ab5f49
