
通过手动或DBUA的方式把数据库升级到12c
删除11g的数据库信息,添加12c数据库的信息(srvctl)
复制密码文件、tnsnames.ora,修改listener.ora等信息

A.在主备库上升级GI(可以先升级主备库GI,再升级数据库。也可先升级备库GI,然后把备库转化为transient logical standby,升级备库上数据库,最后在升级主库上的GI和数据库)
B.把11.2.0.4的物理备库转换成Transient Logical Standby
C.把Transient Logical Standby升级到12.1.0.2
D.Transient Logical Standby继续使用SQL Apply的方式应用主库11.2.0.4的redo
E.通过Switchover把原来11.2.0.4的主库转换成physical Standby,把12.1.0.2的库转换成主库
F.通过应用新升级(12.1.0.2)主库的redo来同步物理备库
H.最后再执行一次Switchover,回到最原始的状态
第一次执行
在Primary database和physical standby database上创建控制文件的备份
在主备库上创建GRP(Guaranteed Restore Points,闪回还原保障点),可以用于还原数据库以防失败
把physical standby转化为transient logical standby
第二次执行
通过使用SQL Apply的方式,把主库的数据同步到transient logical standby
通过Switchover方式,把12c transient logical standby转变为主库
还原原来的主库到之前创建的担保还原点时的状态,并转化为physical standby
第三次执行
在新的physical standby上执行启用redo apply,同步在滚动升级过程中,以及在transient logical stadnby时产生的数据
当同步接近时,在做一次switchover,把数据库的角色转换成升级之前时的状态
注意:脚本执行过程中出错也没关系,可以重复执行
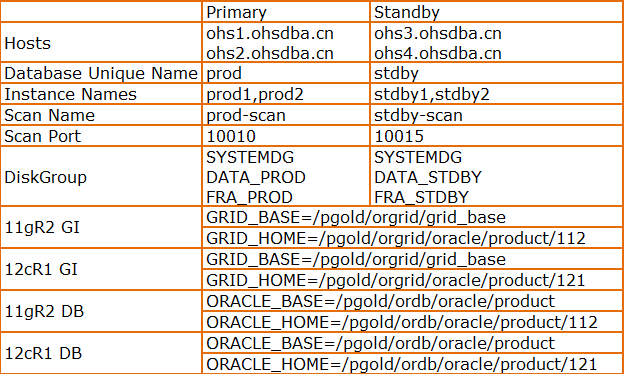
升级环境
First Execution
[oracle@ohs1 ~]$ ./physru.sh sys pri std prod stdby 12.1.0.2.0
Please enter the sysdba password:
### Initialize script to either start over or resume execution
Dec 06 16:52:03 2016 [0-1] Identifying rdbms software version
Dec 06 16:52:03 2016 [0-1] database prod is at version 11.2.0.4.0
Dec 06 16:52:03 2016 [0-1] database stdby is at version 11.2.0.4.0
Dec 06 16:52:03 2016 [0-1] verifying flashback database is enabled at prod and stdby
Dec 06 16:52:04 2016 [0-1] verifying available flashback restore points
Dec 06 16:52:04 2016 [0-1] verifying DG Broker is disabled
Dec 06 16:52:04 2016 [0-1] looking up prior execution history
Dec 06 16:52:04 2016 [0-1] purging script execution state from database prod
Dec 06 16:52:04 2016 [0-1] purging script execution state from database stdby
Dec 06 16:52:04 2016 [0-1] starting new execution of script
### Stage 1: Backup user environment in case rolling upgrade is aborted
Dec 06 16:52:04 2016 [1-1] stopping media recovery on stdby
Dec 06 16:52:06 2016 [1-1] creating restore point PRU_0000_0001 on database stdby
Dec 06 16:52:07 2016 [1-1] backing up current control file on stdby
Dec 06 16:52:08 2016 [1-1] created backup control file /pgold/ordb/oracle/product/112/dbs/PRU_0001_stdby_f.f
Dec 06 16:52:08 2016 [1-1] creating restore point PRU_0000_0001 on database prod
Dec 06 16:52:10 2016 [1-1] backing up current control file on prod
Dec 06 16:52:10 2016 [1-1] created backup control file /pgold/ordb/oracle/product/112/dbs/PRU_0001_prod_f.f
NOTE: Restore point PRU_0000_0001 and backup control file PRU_0001_stdby_f.f
can be used to restore stdby back to its original state as a
physical standby, in case the rolling upgrade operation needs to be aborted
prior to the first switchover done in Stage 4.
### Stage 2: Create transient logical standby from existing physical standby
Dec 06 16:52:10 2016 [2-1] verifying RAC is disabled at stdby
WARN: stdby is a RAC database. Before this script can continue, you
must manually reduce the RAC to a single instance, disable the RAC, and
restart instance stdby1 in mounted mode. This can be accomplished
with the following steps:
1) Shutdown all instances other than instance stdby1.
eg: srvctl stop instance -d stdby -i stdby2 -o abort
2) On instance stdby1, set the cluster_database parameter to FALSE.
eg: SQL> alter system set cluster_database=false scope=spfile;
3) Shutdown instance stdby1.
eg: SQL> shutdown abort;
4) Startup instance stdby1 in mounted mode.
eg: SQL> startup mount;
Once these steps have been performed, enter 'y' to continue the script.
If desired, you may enter 'n' to exit the script to perform the required
steps, and recall the script to resume from this point.
Are you ready to continue? (y/n):.
Dec 06 16:54:18 2016 [2-1] continuing
Dec 06 16:54:18 2016 [2-1] verifying RAC is disabled at stdby
Dec 06 16:54:18 2016 [2-1] verifying database roles
Dec 06 16:54:18 2016 [2-1] verifying physical standby is mounted
Dec 06 16:54:18 2016 [2-1] verifying database protection mode
Dec 06 16:54:18 2016 [2-1] verifying transient logical standby datatype support
Dec 06 16:54:19 2016 [2-2] starting media recovery on stdby
Dec 06 16:54:25 2016 [2-2] confirming media recovery is running
Dec 06 16:54:27 2016 [2-2] waiting for apply lag to fall under 30 seconds
Dec 06 16:54:34 2016 [2-2] apply lag measured at 7 seconds
Dec 06 16:54:34 2016 [2-2] stopping media recovery on stdby
Dec 06 16:54:35 2016 [2-2] executing dbms_logstdby.build on database prod
Dec 06 16:55:01 2016 [2-2] converting physical standby into transient logical standby
Dec 06 16:55:04 2016 [2-3] opening database stdby
Dec 06 16:55:06 2016 [2-4] configuring transient logical standby parameters for rolling upgrade
Dec 06 16:55:07 2016 [2-4] starting logical standby on database stdby
Dec 06 16:55:13 2016 [2-4] waiting until logminer dictionary has fully loaded
Dec 06 16:56:03 2016 [2-4] dictionary load 42% complete
Dec 06 16:56:14 2016 [2-4] dictionary load 75% complete
Dec 06 16:56:24 2016 [2-4] dictionary load is complete
Dec 06 16:56:24 2016 [2-4] waiting for apply lag to fall under 30 seconds
Dec 06 16:56:28 2016 [2-4] apply lag measured at 3 seconds
NOTE: Database stdby is now ready to be upgraded. This script has left the
database open in case you want to perform any further tasks before
upgrading the database. Once the upgrade is complete, the database must
opened in READ WRITE mode before this script can be called to resume the
rolling upgrade.
NOTE: Database stdby may be reverted back to a RAC database upon completion
of the rdbms upgrade. This can be accomplished by performing the
following steps:
1) On instance stdby1, set the cluster_database parameter to TRUE.
eg: SQL> alter system set cluster_database=true scope=spfile;
2) Shutdown instance stdby1.
eg: SQL> shutdown abort;
3) Startup and open all instances for database stdby.
eg: srvctl start database -d stdby
[oracle@ohs1 ~]$ $
Second execution
[oracle@ohs1 ~]$ ./physru.sh sys pri std prod stdby 12.1.0.2.0
Please enter the sysdba password:
### Initialize script to either start over or resume execution
Dec 07 02:10:18 2016 [0-1] Identifying rdbms software version
Dec 07 02:10:18 2016 [0-1] database prod is at version 11.2.0.4.0
Dec 07 02:10:19 2016 [0-1] database stdby is at version 12.1.0.2.0
Dec 07 02:10:19 2016 [0-1] verifying flashback database is enabled at prod and stdby
Dec 07 02:10:19 2016 [0-1] verifying available flashback restore points
Dec 07 02:10:20 2016 [0-1] verifying DG Broker is disabled
Dec 07 02:10:20 2016 [0-1] looking up prior execution history
Dec 07 02:10:20 2016 [0-1] last completed stage [2-4] using script version 0001
Dec 07 02:10:20 2016 [0-1] resuming execution of script
### Stage 3: Validate upgraded transient logical standby
Dec 07 02:10:20 2016 [3-1] database stdby is no longer in OPEN MIGRATE mode
Dec 07 02:10:20 2016 [3-1] database stdby is at version 12.1.0.2.0
### Stage 4: Switch the transient logical standby to be the new primary
Dec 07 02:10:21 2016 [4-1] waiting for stdby to catch up (this could take a while)
Dec 07 02:10:21 2016 [4-1] starting logical standby on database stdby
Dec 07 02:10:22 2016 [4-1] waiting for apply lag to fall under 30 seconds
Dec 07 02:40:26 2016 [4-1] ERROR: timed out after 30 minutes of inactivity
[oracle@ohs1 ~]$
[oracle@ohs1 ~]$ ./physru.sh sys pri std prod stdby 12.1.0.2.0
Please enter the sysdba password:
### Initialize script to either start over or resume execution
Dec 07 17:18:10 2016 [0-1] Identifying rdbms software version
Dec 07 17:18:10 2016 [0-1] database prod is at version 11.2.0.4.0
Dec 07 17:18:10 2016 [0-1] database stdby is at version 12.1.0.2.0
Dec 07 17:18:11 2016 [0-1] verifying flashback database is enabled at prod and stdby
Dec 07 17:18:11 2016 [0-1] verifying available flashback restore points
Dec 07 17:18:11 2016 [0-1] verifying DG Broker is disabled
Dec 07 17:18:12 2016 [0-1] looking up prior execution history
Dec 07 17:18:12 2016 [0-1] last completed stage [3-1] using script version 0001
WARN: The last execution of this script either exited in error or at the
user's request. At this point, there are three available options:
1) resume the rolling upgrade where the last execution left off
2) restart the script from scratch
3) exit the script
Option (2) assumes the user has restored the primary and physical
standby back to the original configuration as required by this script.
Enter your selection (1/2/3): 1
Dec 07 17:18:19 2016 [0-1] resuming execution of script
### Stage 4: Switch the transient logical standby to be the new primary
Dec 07 17:18:20 2016 [4-1] waiting for stdby to catch up (this could take a while)
Dec 07 17:18:20 2016 [4-1] starting logical standby on database stdby
Dec 07 17:18:26 2016 [4-1] waiting for apply lag to fall under 30 seconds
Dec 07 17:18:31 2016 [4-1] apply lag measured at 4 seconds
Dec 07 17:18:32 2016 [4-2] switching prod to become a logical standby
Dec 07 17:19:07 2016 [4-2] prod is now a logical standby
Dec 07 17:19:07 2016 [4-3] waiting for standby stdby to process end-of-redo from primary
Dec 07 17:19:09 2016 [4-4] switching stdby to become the new primary
Dec 07 17:19:17 2016 [4-4] stdby is now the new primary
### Stage 5: Flashback former primary to pre-upgrade restore point and convert to physical
Dec 07 17:19:17 2016 [5-1] verifying instance prod1 is the only active instance
WARN: prod is a RAC database. Before this script can continue, you
must manually reduce the RAC to a single instance. This can be
accomplished with the following step:
1) Shutdown all instances other than instance prod1.
eg: srvctl stop instance -d prod -i prod2 -o abort
Once these steps have been performed, enter 'y' to continue the script.
If desired, you may enter 'n' to exit the script to perform the required
steps, and recall the script to resume from this point.
Are you ready to continue? (y/n): y
Dec 07 17:21:41 2016 [5-1] continuing
Dec 07 17:21:41 2016 [5-1] verifying instance prod1 is the only active instance
Dec 07 17:21:41 2016 [5-1] shutting down database prod
Dec 07 17:22:57 2016 [5-1] mounting database prod
Dec 07 17:23:13 2016 [5-2] flashing back database prod to restore point PRU_0000_0001
Dec 07 17:23:15 2016 [5-3] converting prod into physical standby
Dec 07 17:23:15 2016 [5-4] shutting down database prod
NOTE: Database prod has been shutdown, and is now ready to be started
using the newer version Oracle binary. This script requires the
database to be mounted (on all active instances, if RAC) before calling
this script to resume the rolling upgrade.
NOTE: Database prod is no longer limited to single instance operation since
the database has been successfully converted into a physical standby.
For increased availability, Oracle recommends starting all instances in
the RAC on the newer binary by performing the following step:
1) Startup and mount all instances for database prod
eg: srvctl start database -d prod -o mount
[oracle@ohs1 ~]$
Third execution
[oracle@ohs1 ~]$ ./physru.sh sys pri std prod stdby 12.1.0.2.0
Please enter the sysdba password:
### Initialize script to either start over or resume execution
Dec 07 18:09:21 2016 [0-1] Identifying rdbms software version
Dec 07 18:09:21 2016 [0-1] database prod is at version 12.1.0.2.0
Dec 07 18:09:21 2016 [0-1] database stdby is at version 12.1.0.2.0
Dec 07 18:09:23 2016 [0-1] verifying flashback database is enabled at prod and stdby
Dec 07 18:09:23 2016 [0-1] verifying available flashback restore points
Dec 07 18:09:23 2016 [0-1] verifying DG Broker is disabled
Dec 07 18:09:24 2016 [0-1] looking up prior execution history
Dec 07 18:09:24 2016 [0-1] last completed stage [5-4] using script version 0001
Dec 07 18:09:24 2016 [0-1] resuming execution of script
### Stage 6: Run media recovery through upgrade redo
Dec 07 18:09:26 2016 [6-1] upgrade redo region identified as scn range [1328223, 2589965]
Dec 07 18:09:26 2016 [6-1] starting media recovery on prod
Dec 07 18:09:32 2016 [6-1] confirming media recovery is running
Dec 07 18:09:33 2016 [6-1] waiting for media recovery to initialize v$recovery_progress
Dec 07 18:09:55 2016 [6-1] monitoring media recovery's progress
Dec 07 18:09:57 2016 [6-3] recovery of upgrade redo at 05% - estimated complete at Dec 07 18:16:18
Dec 07 18:10:14 2016 [6-3] recovery of upgrade redo at 06% - estimated complete at Dec 07 18:21:08
Dec 07 18:10:31 2016 [6-3] recovery of upgrade redo at 12% - estimated complete at Dec 07 18:16:58
Dec 07 18:10:48 2016 [6-3] recovery of upgrade redo at 20% - estimated complete at Dec 07 18:15:30
Dec 07 18:11:04 2016 [6-3] recovery of upgrade redo at 24% - estimated complete at Dec 07 18:15:32
Dec 07 18:11:21 2016 [6-3] recovery of upgrade redo at 28% - estimated complete at Dec 07 18:15:39
Dec 07 18:11:38 2016 [6-3] recovery of upgrade redo at 33% - estimated complete at Dec 07 18:15:44
Dec 07 18:11:55 2016 [6-3] recovery of upgrade redo at 35% - estimated complete at Dec 07 18:16:05
Dec 07 18:12:11 2016 [6-3] recovery of upgrade redo at 38% - estimated complete at Dec 07 18:16:26
Dec 07 18:12:28 2016 [6-3] recovery of upgrade redo at 43% - estimated complete at Dec 07 18:16:14
Dec 07 18:12:45 2016 [6-3] recovery of upgrade redo at 46% - estimated complete at Dec 07 18:16:24
Dec 07 18:13:02 2016 [6-3] recovery of upgrade redo at 51% - estimated complete at Dec 07 18:16:16
Dec 07 18:13:18 2016 [6-3] recovery of upgrade redo at 57% - estimated complete at Dec 07 18:16:05
Dec 07 18:13:35 2016 [6-3] recovery of upgrade redo at 60% - estimated complete at Dec 07 18:16:14
Dec 07 18:13:52 2016 [6-3] recovery of upgrade redo at 64% - estimated complete at Dec 07 18:16:14
Dec 07 18:14:08 2016 [6-3] recovery of upgrade redo at 70% - estimated complete at Dec 07 18:16:00
Dec 07 18:14:25 2016 [6-3] recovery of upgrade redo at 73% - estimated complete at Dec 07 18:16:07
Dec 07 18:14:42 2016 [6-3] recovery of upgrade redo at 80% - estimated complete at Dec 07 18:15:56
Dec 07 18:14:59 2016 [6-3] recovery of upgrade redo at 83% - estimated complete at Dec 07 18:16:03
Dec 07 18:15:15 2016 [6-3] recovery of upgrade redo at 87% - estimated complete at Dec 07 18:16:05
Dec 07 18:15:32 2016 [6-3] recovery of upgrade redo at 89% - estimated complete at Dec 07 18:16:12
Dec 07 18:15:49 2016 [6-3] recovery of upgrade redo at 91% - estimated complete at Dec 07 18:16:22
Dec 07 18:16:05 2016 [6-4] media recovery has finished recovering through upgrade
### Stage 7: Switch back to the original roles prior to the rolling upgrade
NOTE: At this point, you have the option to perform a switchover
which will restore prod back to a primary database and
stdby back to a physical standby database. If you answer 'n'
to the question below, prod will remain a physical standby
database and stdby will remain a primary database.
Do you want to perform a switchover? (y/n): y
Dec 07 18:31:36 2016 [7-1] continuing
Dec 07 18:31:36 2016 [7-2] verifying instance stdby1 is the only active instance
WARN: stdby is a RAC database. Before this script can continue, you
must manually reduce the RAC to a single instance. This can be
accomplished with the following step:
1) Shutdown all instances other than instance stdby1.
eg: srvctl stop instance -d stdby -i stdby2
Once these steps have been performed, enter 'y' to continue the script.
If desired, you may enter 'n' to exit the script to perform the required
steps, and recall the script to resume from this point.
Are you ready to continue? (y/n): y
Dec 07 18:32:43 2016 [7-2] continuing
Dec 07 18:32:43 2016 [7-2] verifying instance stdby1 is the only active instance
Dec 07 18:32:45 2016 [7-2] waiting for apply lag to fall under 30 seconds
Dec 07 18:33:15 2016 [7-2] apply lag measured at 30 seconds
Dec 07 18:33:16 2016 [7-3] switching stdby to become a physical standby
Dec 07 18:33:20 2016 [7-3] stdby is now a physical standby
Dec 07 18:33:20 2016 [7-3] shutting down database stdby
Dec 07 18:33:22 2016 [7-3] mounting database stdby
Dec 07 18:33:35 2016 [7-4] waiting for standby prod to process end-of-redo from primary
Dec 07 18:33:36 2016 [7-5] switching prod to become the new primary
Dec 07 18:33:37 2016 [7-5] prod is now the new primary
Dec 07 18:33:37 2016 [7-5] opening database prod
Dec 07 18:33:49 2016 [7-6] starting media recovery on stdby
Dec 07 18:33:55 2016 [7-6] confirming media recovery is running
NOTE: Database prod has completed the switchover to the primary role, but
instance prod1 is the only open instance. For increased availability,
Oracle recommends opening the remaining active instances which are
currently in mounted mode by performing the following steps:
1) Shutdown all instances other than instance prod1.
eg: srvctl stop instance -d prod -i prod2
2) Startup and open all inactive instances for database prod.
eg: srvctl start database -d prod
NOTE: Database stdby is no longer limited to single instance operation since
it has completed the switchover to the physical standby role. For
increased availability, Oracle recommends starting the inactive
instances in the RAC by performing the following step:
1) Startup and mount inactive instances for database stdby
eg: srvctl start database -d stdby -o mount
### Stage 8: Statistics
script start time: 06-Dec-16 16:52:06
script finish time: 07-Dec-16 18:33:59
total script execution time: +01 01:41:53
wait time for user upgrade: +00 09:13:53
active script execution time: +00 16:28:00
transient logical creation start time: 06-Dec-16 16:54:19
transient logical creation finish time: 06-Dec-16 16:55:04
primary to logical switchover start time: 07-Dec-16 17:18:31
logical to primary switchover finish time: 07-Dec-16 17:19:17
primary services offline for: +00 00:00:46
total time former primary in physical role: +00 01:08:12
time to reach upgrade redo:
time to recover upgrade redo: +00 00:06:09
primary to physical switchover start time: 07-Dec-16 18:31:36
physical to primary switchover finish time: 07-Dec-16 18:33:48
primary services offline for: +00 00:02:12
SUCCESS: The physical rolling upgrade is complete
[oracle@ohs1 ~]$
Reference
Oracle11g Data Guard: Database Rolling Upgrade Shell Script (Doc ID 949322.1)
http://docs.oracle.com/database/122/SBYDB/upgrading-patching-downgrading-oracle-data-guard-configuration.htm
http://docs.oracle.com/cd/E11882_01/em.112/e12255/oui7_opatch.htm
