
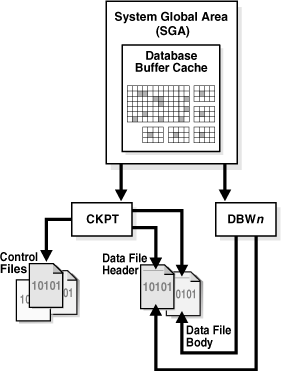
CKPT
Checkpoint Process,it signals DBWn at checkpoints and updates all the data files and control files of the database to indicate the most recent checkpoint
At specific times CKPT starts a checkpoint request by messaging DBWn to begin writing dirty buffers. On completion of individual checkpoint requests, CKPT updates data file headers and control files to record most recent checkpoint.
CKPT checks every three seconds to see whether the amount of memory exceeds the value of the PGA_AGGREGATE_LIMIT initialization parameter, and if so, takes the action described in "PGA_AGGREGATE_LIMIT".
See Also: Oracle Database Concepts
Concepts
A checkpoint corresponds to a data structure that defines a SCN in the redo thread of a database. Checkpoints are recorded in the control file and each datafile header, and are a crucial element of recovery.
When a checkpoint occurs, Oracle must update the headers of all datafiles to record the details of the checkpoint. This is done by the CKPT process. The CKPT process does not write blocks to disk, DBWn (DB Writer Process) always performs that task.
A Checkpoint is a crucial mechanism in consistent database shutdowns, instance recovery, and Oracle Database operation generally. The term checkpoint has the following related meanings:
A data structure that indicates the checkpoint position, which is the SCN in the redo stream where instance recovery must begin. The checkpoint position is determined by the oldest dirty buffer in the database buffer cache. The checkpoint position acts as a pointer to the redo stream and is stored in the control file and in each data file header.
The writing of modified database buffers in the database buffer cache to disk.
The checkpoint process (CKPT) updates the control file and data file headers with checkpoint information and signals DBWn to write blocks to disk. Checkpoint information includes the checkpoint position, SCN, location in online redo log to begin recovery, and so on.
LGWR Process writes redo from log buffer to online redo log files for following reasons:
Every 3 Seconds
When Commit Occurs
When Log buffer is 1/3 full
When Log buffer is 1 MB full.
DBWR Processes writes the dirty buffers to disk only on certain conditions:
A shadow process must scan more than one-quarter of the db_block_buffer parameter.
Every three seconds.
When a checkpoint is produced.
Dirty
buffers are maintained on the buffer cache checkpoint queues in low RBA
order。RBA就是Redo Byte Address,通过这个地址可以定位重做日志块。RBA由三个部分组成:
The log file sequence number (4 bytes)
The log file block number (4 bytes)
The byte offset into the block at which the redo record starts (2 bytes)
Low RBA
low RBA is the address of the redo for the first change that was applied to the block since it was last clean
Buffer Cache中一个脏块第一次被更新的时候产生的重做日志记录在重做日志文件中所对应的位置
High RBA
high RBA is the address of the redo for the most recent change to have been applied to the block.
Buffer Cache中一个脏块最近一次被更新的时候产生的重做日志记录在重做日志文件中所对应的位置
Checkpoint RBA
Checkpoint RBA is the point up to which DBWn has written buffers from the checkpoint queues if incremental checkpointing is enabled -- otherwise it is the RBA of last full thread checkpoint. The checkpoint RBA is copied into the checkpoint progress record of the controlfile by the checkpoint heartbeat once every 3 seconds. Instance recovery, when needed, begins from the checkpoint RBA recorded in the controlfile
当 checkpoint事件发生时,Checkpoint进程会记录下当前所写的重做日志块的地址即RBA,这个RBA被称为checkpoint RBA。自上一次Checkpoint RBA到当前的Checkpoint RBA之间在Buffer Cache中的脏块将会被写入到数据文件当中去。并不是只有在检查点的情况下DBWR进程才写脏数据到Disk中,在Cache Buffer空间不足的情况下,不管是否发生检查点,DBWR都会将脏块写入到Disk中
Ondisk RBA
The on-disk RBA is the point up to which LGWR has flushed the redo thread to the online log files. DBWn may not write a block for which the high RBA is beyond the on-disk RBA. Otherwise transaction recovery (rollback) would not be possible, because the redo needed to undo a change is always in the same redo record as the redo for the change itself.
LGWR已经把log buffer中的日志刷到在线日志文件的位置
Target RBA
The target RBA is the point up to which DBWn should seek to advance the checkpoint RBA to satisfy instance recovery objectives.
目标RBA是指为了满足恢复需求DBWn所应写到的位置
Sync RBA
The term sync RBA is sometimes used to refer to the point up to which LGWR is required to sync the thread.
However, this is not a full RBA -- only a redo block number is used at this point.
The incremental checkpoint RBA and the on-disk RBA can also be seen in X$KCCCP.The full thread checkpoint RBA can be seen in X$KCCRT.
Checkpoint做了什么
1.Every dirty block in the buffer cache is written to the data files. That is, it synchronizes the datablocks in the buffer cache with the datafiles on disk. It's the DBWR that writes all modified databaseblocks back to the datafiles.
2.The latest SCN is written (updated) into the datafile header.
3.The latest SCN is also written to the controlfiles.
The update of the datafile headers and the control files is done by the LGWR(CKPT if CKPT is enabled). As of version 8.0, CKPT is enabled by default.
更新SCN的任务由CKPT进程完成,在Oracle 8.0之后CKPT进程默认是被启用的,如果CKPT进程没有启用的话那相应的操作将由LGWR进程完成。在早期版本中,由LGWR完成,后来为减轻LGWR的负担,改由CKPT来进行
Reduce the time required for recovery in case of an instance or media failure
减少Instance/Media failure所需的时间。如果脏块过多,实例恢复的时间会很长,检查点的发生可以减少脏块的数量,从而提高实例恢复的时间
Ensure that dirty buffers in the buffer cache are written to disk regularly and all committed data is written to disk during a consistent shutdown
保证在Buffer Cache中的脏块被写入Disk,保证数据的一致性
Checkpoint的分类
Thread checkpoints
A Redo log thread is a set of operating system files in which an instance records all changes it makes - committed and uncommitted - to memory buffers containing datafile blocks. The redo log is organized into redo threads. The redo log of a single-instance (non-Parallel Server / RAC option) database consists of a single thread. A Parallel Server/Real Application Cluster redo log has a thread per instance.
A thread checkpoint event guarantees that all pre-thread-checkpoint-SCN redo generated in that thread for all online datafiles has been written to disk. The database writes to disk all buffers modified by redo in a specific thread before Thread Checkpoint SCN. The set of thread checkpoints on all instances in a database is a database checkpoint.
A.对于单节点数据库,只有一个thread,switch logfile发起的对当前thread的CheckPoint,就是整个数据库的CheckPoint,所以log switch会导致v$datafile(v$datafile_header)中的CheckPoint_change#改变,CheckPoint完成以后会更新为最新值。
B.对于2个以上节点的RAC数据库,至少存在2个以上的thread,单一的thread的log switch并不会触发v$datafile(v$datafile_header)的CheckPoint_change#的修改。因为单一的thread的CheckPoint,只会触发在此节点上脏块的写回,其他的节点可能存在在此CheckPoint SCN之前的脏块,对于数据文件/数据库来说,这并不是一个完整的CheckPoint。在RAC中,只有所有节点间的全局检查点(global CheckPoint,alter system CheckPoint)会导致v$datafile中的CheckPoint_change#的变化。
Tablespace and data file checkpoints
The database writes to disk all buffers modified by redo before a specific target. A tablespace checkpoint is a set of data file checkpoints, one for each data file in the tablespace. These checkpoints occur in a variety of situations, including making a tablespace read-only or taking it offline normal, shrinking a data file, or executing ALTER TABLESPACE BEGIN BACKUP.
Incremental checkpoints
An incremental checkpoint is a type of thread checkpoint partly intended to avoid writing large numbers of blocks at online redo log switches. DBWn checks at least every three seconds to determine whether it has work to do. When DBWn writes dirty buffers, it advances the checkpoint position, causing CKPT to write the checkpoint position to the control file, but not to the data file headers.
Other types of checkpoints
including instance and media recovery checkpoints and checkpoints when schema objects are dropped or truncated.
触发检查点的操作
shutdown instance(except abort)
alter system checkpoint
alter system switch logfile;
Log switches cause checkpoints. Checkpoints do not cause log switches.
When the checkpoint is complete, the redo logs that protected the checkpointed data are not needed for instance recovery anymore.
alter system checkpoint local;
alter system checkpoint global; #for RAC
log file switch normal;
When the delay for LOG_CHECKPOINT_TIMEOUT is reached.
When the size in bytes corresponding to (LOG_CHECKPOINT_INTERVAL* size of IO OS blocks) is written on the current redo log file.
init parameters fast_start_mttr_target
alter tablespace begin/end backup
alter tablespace datafile online/offline
alter tablespace/datafile read only
drop table ohsdba;
truncate table ohsdba;
Normal checkpoint and Incremental checkpoint的不同
Normal checkpoint will update the control file as well as all datafile headers.
发生完全检查点时控制文件和数据文件头中的checkpoint scn都会被更新
Incremental checkpoint will update only the control file.
发生增量检查点时只有控制文件中的checkpoint scn更新;
Incremental checkpoint is:
> Continuously active checkpoint
增量checkpoint是一直持续的
> no completion RBA
没有checkpoint RBA,因为这个checkpoint是一直都在进行的
> checkpoint advanced in memory only
> RBA for incremental checkpoint recorded in control file
增量checkpoint的RBA信息记录在控制文件中
> DBW0 writes out dirty buffers to advance the incremental checkpoint.
> Used to reduce recovery time after a failure
增量checkpoint可以减少实例恢复时间
Incremental checkpoint is determined by:
> Upper bound on recovery needs.
> size of the smallest log file
> value of log_checkpoint_interval
> value of log_checkpoint_timeout
> Total numbers of dirty buffers in the cache.
Checkpoint相关参数
col name for a35
col description for a60
col value for a10
col isdefault for a10
col ismodified for a10
col isadjusted for a10
set pages 1000 lines 156
SELECT i.ksppinm name,
cv.ksppstvl value,
cv.ksppstdf isdefault,
DECODE (BITAND (CV.ksppstvf, 7),
1, 'MODIFIED',
4, 'SYSTEM_MOD',
'FALSE')
ismodified,
DECODE (BITAND (CV.ksppstvf, 2), 2, 'TRUE', 'FALSE') isadjusted,
i.ksppdesc description
FROM sys.x$ksppi i, sys.x$ksppcv cv
WHERE i.inst_id = USERENV ('Instance')
AND CV.inst_id = USERENV ('Instance')
and i.indx = cv.indx
and i.ksppinm like '%&1%'
order by replace (i.ksppinm, '_', '');
Enter value for 1: checkpoint
old 15: and i.ksppinm like '%&1%'
new 15: and i.ksppinm like '%checkpoint%'
NAME VALUE ISDEFAULT ISMODIFIED ISADJUSTED DESCRIPTION ----------------------------------- ---------- ---------- ---------- ---------- ------------------------------------------------------------ _disable_incremental_checkpoints FALSE TRUE FALSE FALSE Disable incremental checkpoints for thread recovery _disable_selftune_checkpointing FALSE TRUE FALSE FALSE Disable self-tune checkpointing _gc_global_checkpoint_scn TRUE TRUE FALSE FALSE if TRUE, enable global checkpoint scn _kdli_checkpoint_flush FALSE TRUE FALSE FALSE do not invalidate cache buffers after write log_checkpoint_interval 0 TRUE FALSE FALSE # redo blocks checkpoint threshold _log_checkpoint_recovery_check 0 TRUE FALSE FALSE # redo blocks to verify after checkpoint log_checkpoints_to_alert FALSE TRUE FALSE FALSE log checkpoint begin/end to alert file log_checkpoint_timeout 10 TRUE SYSTEM_MOD FALSE Maximum time interval between checkpoints in seconds _selftune_checkpointing_lag 300 TRUE FALSE FALSE Self-tune checkpointing lag the tail of the redo log _selftune_checkpoint_write_pct 3 TRUE FALSE FALSE Percentage of total physical i/os for self-tune ckpt 10 rows selected.
log_checkpoint_interval
这个参数指定了两次incremental checkpoint之间所允许的redo的量,单位是操作系统块,不是数据库的块。如果这个值为0,没有实际意义。
log_checkpoint_timeout
单位是秒,从上次incremental checkpoint之后算起,这个参数也意味着在Buffer Cache中的脏数据存在的时间不能超过这个时间。如果设置为0,意味着禁用基于时间的Checkpoints。设置为0是不推荐的,除非设置了FAST_START_MTTR_TARGET
fast_start_mttr_target
这个参数指定了实例恢复所需的时间,单位是秒(0~3600)。如果这个参数设置,会覆盖LOG_CHECKPOINT_INTERVAL的值
fast_start_io_target
(available only with the Oracle Enterprise Edition) specifies the number of I/Os that should be
needed during crash or instance recovery. When you set this parameter, DBWn writes dirty buffers
out more aggressively, so that the number of blocks that must be processed during recovery stays
below the value specified in the parameter. However, this parameter does not impose a hard limit
on the number of recovery I/Os. Under transient workload situations, the number of I/Os needed
during recovery may be greater than the value specified in this parameter. In such situations,
DBWn will not slow down database activity.
log_checkpoints_to_alert
Enable this parameter will update checkpoint info to alert logfile,the message like below
Incremental checkpoint up to RBA [0xff.f3c.0], current log tail at RBA [0xff.f3f.0]
各种Checkpoint RBA的顺序
节点一
SQL> select 'Low RBA: '||cplrba_seq||'.'||cplrba_bno||'.'||cplrba_bof RBA from x$kcccp where cpsta !=0
2 union
3 select 'x$KCVFH RBA: '||FHRBA_SEQ||'.'||FHRBA_BNO||'.'||FHRBA_BOF from x$kcvfh
4 union
5 select 'Ondisk RBA: '||cpodr_seq||'.'||cpodr_bno||'.'||cpodr_bof from x$kcccp where cpsta !=0
6 union
7 select 'Target RBA: '||target_rba_seq||'.'||target_rba_bno||'.'||target_rba_bof from x$targetrba
8 union
9 select 'Thread RBA: '||rtckp_rba_seq||'.'||rtckp_rba_bno||'.'||rtckp_rba_bof from x$kccrt
10 union
11 select 'x$BH RBA: '||max(lrba_seq)||'.'||max(lrba_bno) from x$bh;
RBA
--------------------------------------------------------------------------------
Low RBA: 5902.53804.0
Low RBA: 7282.116788.0
Ondisk RBA: 5902.54272.0
Ondisk RBA: 7282.125217.0
Target RBA: 7281.168667.16
Thread RBA: 5902.2.16
Thread RBA: 7282.2.16
x$BH RBA: 7282.125193
x$KCVFH RBA: 7282.2.16
9 rows selected.
SQL> archive log list;
Database log mode Archive Mode
Automatic archival Enabled
Archive destination USE_DB_RECOVERY_FILE_DEST
Oldest online log sequence 7281
Next log sequence to archive 7282
Current log sequence 7282
SQL>
节点二
SQL> select 'Low RBA: '||cplrba_seq||'.'||cplrba_bno||'.'||cplrba_bof RBA from x$kcccp where cpsta !=0
2 union
3 select 'x$KCVFH RBA: '||FHRBA_SEQ||'.'||FHRBA_BNO||'.'||FHRBA_BOF from x$kcvfh
4 union
5 select 'Ondisk RBA: '||cpodr_seq||'.'||cpodr_bno||'.'||cpodr_bof from x$kcccp where cpsta !=0
6 union
7 select 'Target RBA: '||target_rba_seq||'.'||target_rba_bno||'.'||target_rba_bof from x$targetrba
8 union
9 select 'Thread RBA: '||rtckp_rba_seq||'.'||rtckp_rba_bno||'.'||rtckp_rba_bof from x$kccrt
10 union
11 select 'x$BH RBA: '||max(lrba_seq)||'.'||max(lrba_bno) from x$bh;
RBA
--------------------------------------------------------------------------------
Low RBA: 5902.53804.0
Low RBA: 7282.116853.0
Ondisk RBA: 5902.54306.0
Ondisk RBA: 7282.125357.0
Target RBA: 5901.26153.16
Thread RBA: 5902.2.16
Thread RBA: 7282.2.16
x$BH RBA: 5902.54285
x$KCVFH RBA: 7282.2.16
9 rows selected.
SQL> archive log list;
Database log mode Archive Mode
Automatic archival Enabled
Archive destination USE_DB_RECOVERY_FILE_DEST
Oldest online log sequence 5901
Next log sequence to archive 5902
Current log sequence 5902
SQL>
通过观察,我们可以发现RBA大小顺序依次为:Thread RBA-->Low RBA-->Target RBA-->Ondisk RBA
恢复的起点和终点
由于Low RBA是增量RBA,她的值总是比Thread RBA值要大一些,当数据库Crash后需要恢复时,会从Low RBA起读取并应用Redo,这就是数据库恢复的起点,直到On Disk RBA的位置(恢复的终点),可以通过日志看出。
Checkpoint查询
select 'Low RBA: '||cplrba_seq||'.'||cplrba_bno||'.'||cplrba_bof RBA from x$kcccp where cpsta !=0
union
select 'Ondisk RBA: '||cpodr_seq||'.'||cpodr_bno||'.'||cpodr_bof from x$kcccp where cpsta !=0
union
select 'Target RBA: '||target_rba_seq||'.'||target_rba_bno||'.'||target_rba_bof from x$targetrba
union
select 'Thread RBA: '||rtckp_rba_seq||'.'||rtckp_rba_bno||'.'||rtckp_rba_bof from x$kccrt
union
select 'x$BH Low RBA: '||max(lrba_seq)||'.'||max(lrba_bno) from x$bh
union
select 'x$KCVFH RBA: '||FHRBA_SEQ||'.'||FHRBA_BNO||'.'||FHRBA_BOF from x$kcvfh;
select
le.leseq log_sequence#,
substr(to_char(100 * cp.cpodr_bno / le.lesiz, '999.00'), 2) || '%' used
from
sys.x$kcccp cp,
sys.x$kccle le
where
le.inst_id = userenv('Instance') and
cp.inst_id = userenv('Instance') and
le.leseq = cp.cpodr_seq
/
select cptno checkpoint_number,
cpsta checkpoint_status,
cpdrt dirty_blocks ,
cprdb dirty_redo_blocks,
cplrba_seq||'.'||cplrba_bno||'.'||cplrba_bof Low_rba,
cpodr_seq||'.'||cpodr_bno||'.'||cpodr_bof Ondisk_rba,
cpods ondisk_scn,
cpodt ondisk_time,
cpodt_i checktime2number,
cphbt heartbeat
from x$kcccp;
select rtckp_thr thread,
rtckp_scn scn,
rtckp_tim time,
rtckp_rba_seq||'.'||rtckp_rba_bno||'.'||rtckp_rba_bof Thread_RBA
from x$kccrt;
select logfilesz,
totallogsz,
lglogsz,
cur_est_rcv_reads,
actual_redo_blks,
target_rba_seq||'.'||target_rba_bno||'.'||target_rba_bof Target_RBA,
ct_lag checkpoint_timeout_lag,ci_lag checkpoint_interval_lag from x$targetrba;
Reference
http://www.ixora.com.au/notes/rba.htm
